Understanding Defects Management
Overview of Defect Management Stages
The Defect Management Lifecycle is made up of several structured stages, each designed to ensure that defects are handled efficiently, transparently, and with traceability throughout the software development process.
- Defect Identification: The process begins when a defect is discovered during unit testing, integration testing, UAT, static analysis, or via end-user feedback.
- Defect Logging: Each identified defect is documented in a tracking system with key information such as a unique ID, severity, steps to reproduce, environment details, and assignment.
- Defect Triage: In triage sessions, a cross-functional team validates the defect, evaluates its impact, sets priority, and assigns ownership for resolution.
- Defect Resolution: Developers work on the fix by modifying code, performing local testing, and passing it through peer reviews or quality gates.
- Retesting: The QA team verifies that the fix works by repeating the original reproduction steps and executing relevant regression tests to ensure nothing else broke.
- Closure: Once a defect is successfully retested, it is closed with final documentation that confirms its resolution, including comments or test evidence if applicable.
This structured lifecycle helps teams maintain quality, prioritise effort, and build a feedback loop for continuous improvement in both code and process.
Defect Management Lifecycle
The Defect Management Lifecycle consists of a series of structured stages aimed at ensuring that every defect is properly captured, tracked, resolved, and closed in a consistent and traceable manner. These stages help development and QA teams manage issues efficiently and reduce risk throughout the software delivery process.
a) Defect Identification
Defects are initially discovered through various means, including:
- Unit testing
- Integration/system testing
- User acceptance testing (UAT)
- End-user feedback
- Static code analysis
b) Defect Logging
Once identified, the defect is recorded in a defect tracking system with relevant details such as:
- Unique identifier
- Title and detailed description
- Steps to reproduce
- Severity and priority
- Affected environment or platform
- Attachments like screenshots or logs
- Assigned owner or team
c) Defect Triage
Triage meetings are held to:
- Validate the defect’s existence and relevance
- Assess its technical impact and business urgency
- Assign proper severity and priority
- Allocate the issue to the appropriate team or developer
d) Defect Resolution
During this phase, developers:
- Analyse root causes
- Implement code changes or configuration fixes
- Perform unit tests and peer reviews before passing it on
e) Retesting
The QA team verifies the fix by:
- Reproducing the original test scenario
- Running related regression tests
- Reopening the defect if the issue persists
f) Closure
Once a defect is confirmed as fixed:
- It is marked as “Resolved” or “Closed”
- Testing evidence and comments are added to the record
- Metrics may be updated to support further analysis
This structured approach helps teams improve software quality, reduce defect leakage, and feed insights into preventive actions such as code reviews, automation, and training.
In software engineering, defect management isn’t just about fixing bugs — it’s about recognising where they happen, why they cluster, and how they correlate with complexity and quality practices. One key question teams often overlook is:
“If my application has 100 features, how many of them should I expect to contain defects?”
Defect Metrics
Defect metrics provide valuable insights into the health of a software product and the effectiveness of the development and QA processes. Commonly used metrics include Defect Density, which measures the number of defects per 1,000 lines of code (KLOC), offering a general view of code quality. Defect Leakage indicates how many defects escaped to production compared to those caught during testing, highlighting the efficiency of internal QA. Defect Removal Efficiency (DRE) tracks how well the team catches defects before release, calculated as the ratio of defects fixed before release over the total number of defects found. Mean Time to Repair (MTTR) measures the average time taken to resolve a defect, which helps gauge responsiveness and resolution speed. Another important metric is the Reopen Rate, which shows how often resolved defects are reopened due to incomplete or incorrect fixes. These metrics are essential for continuous improvement and help guide quality assurance strategies, resource planning, and release readiness assessments.
Defect Density
Defects per 1,000 lines of code (KLOC)
| Module | LOC | Defects Found | Defect Density |
|---|---|---|---|
| Authentication | 3,000 | 12 | 4.0 / KLOC |
| Billing | 4,500 | 5 | 1.1 / KLOC |
| Dashboard | 2,000 | 6 | 3.0 / KLOC |
Defect Leakage
% of defects discovered after release
| Release Version | Total Defects Found | Post-Release Defects | Defect Leakage Rate |
|---|---|---|---|
| v1.0 | 60 | 10 | 16.7% |
| v1.1 | 45 | 3 | 6.7% |
Defect Removal Efficiency (DRE)
Measures effectiveness of defect detection before release
DRE = (Defects fixed before release / Total defects found) × 100
| Release | Pre-Release Fixes | Post-Release Defects | DRE |
|---|---|---|---|
| v1.0 | 50 | 10 | 83.3% |
| v1.1 | 42 | 3 | 93.3% |
Mean Time to Repair (MTTR)
Average time to resolve a defect
| Defect ID | Reported At | Resolved At | MTTR (Hours) |
|---|---|---|---|
| BUG-101 | 2025-04-01 10:00 | 2025-04-01 16:00 | 6 |
| BUG-102 | 2025-04-02 09:00 | 2025-04-02 18:00 | 9 |
| Average | 7.5 |
Reopen Rate
Percentage of resolved defects reopened
| Sprint | Resolved Defects | Reopened Defects | Reopen Rate |
|---|---|---|---|
| Sprint 12 | 40 | 4 | 10% |
| Sprint 13 | 35 | 1 | 2.9% |
How Bugs Are Distributed Across Features
Contrary to a uniform distribution, bugs tend to concentrate in specific parts of the system. Industry data and empirical observations suggest:
| Project Quality | Estimated % of Bug-Affected Features |
|---|---|
| High Quality (CI/CD, mature testing) | 15–30% |
| Average Quality (typical teams) | 30–50% |
| Low Quality (rushed, poor coverage) | 50–70% |
So in a 100-feature application:
- A high-quality product may have only 15 to 30 features with bugs during QA.
- An average project might have 30 to 50 affected features.
- Less mature or legacy systems could see 50 or more features containing defects.
Why Not All Features?
This is largely due to the Pareto Principle — where 80% of defects are often found in just 20% of the features. These tend to be:
- Complex modules with branching logic
- Features under frequent change
- Highly integrated components
- Those with vague or shifting requirements
Meanwhile, simpler or stable features (like static pages or utility functions) often go untouched by defects.
Tracking the Right Metric
A useful internal KPI is:
Feature Defect Coverage (%) = (Features with ≥1 defect / Total Features) × 100
This helps identify systemic weaknesses in QA, development, or requirements clarity. Lowering this percentage over time is a sign of improving code quality and testing effectiveness.
Environment-Specific Misclassifications
A common pitfall in defect management arises when QA teams report issues found in non-production environments as formal defects or bugs. While these findings are valuable during the testing process, it’s important to recognise that not all issues identified in staging or development environments qualify as true defects. Environments may differ in configuration, data consistency, or deployment state—often sharing space with other ongoing feature work or incomplete tasks. As a result, a reported issue may be a side effect of an unstable or contaminated environment rather than a reproducible problem in the actual product. For a defect to be formally classified as a bug, it must be verified as reproducible in an isolated, properly configured environment—and ultimately, in production. Misclassifying environment-specific anomalies as bugs can lead to unnecessary noise in the defect backlog and misdirected development effort.
Checklist: Before Logging a Defect / Bug
Use the following checklist to confirm whether an issue should be logged as a valid defect:
- Can the issue be reproduced reliably in a clean, isolated environment?
- Is the affected environment configured correctly and not polluted by other incomplete deployments?
- Have all caches, background jobs, and dependent services been restarted or validated?
- Has the issue been reproduced outside of development branches or experimental builds?
- Have you ruled out data inconsistencies or missing test data as the cause?
- Has the issue been peer-reviewed or confirmed by another QA/dev team member?
- Does the issue violate functional requirements, user expectations, or documented behaviour?
- Is there a clear impact on user experience, functionality, or system stability?
Only if most or all of these boxes are checked should the issue be formally logged as a defect. Otherwise, it may be more appropriate to track it as an environment issue or internal test note.
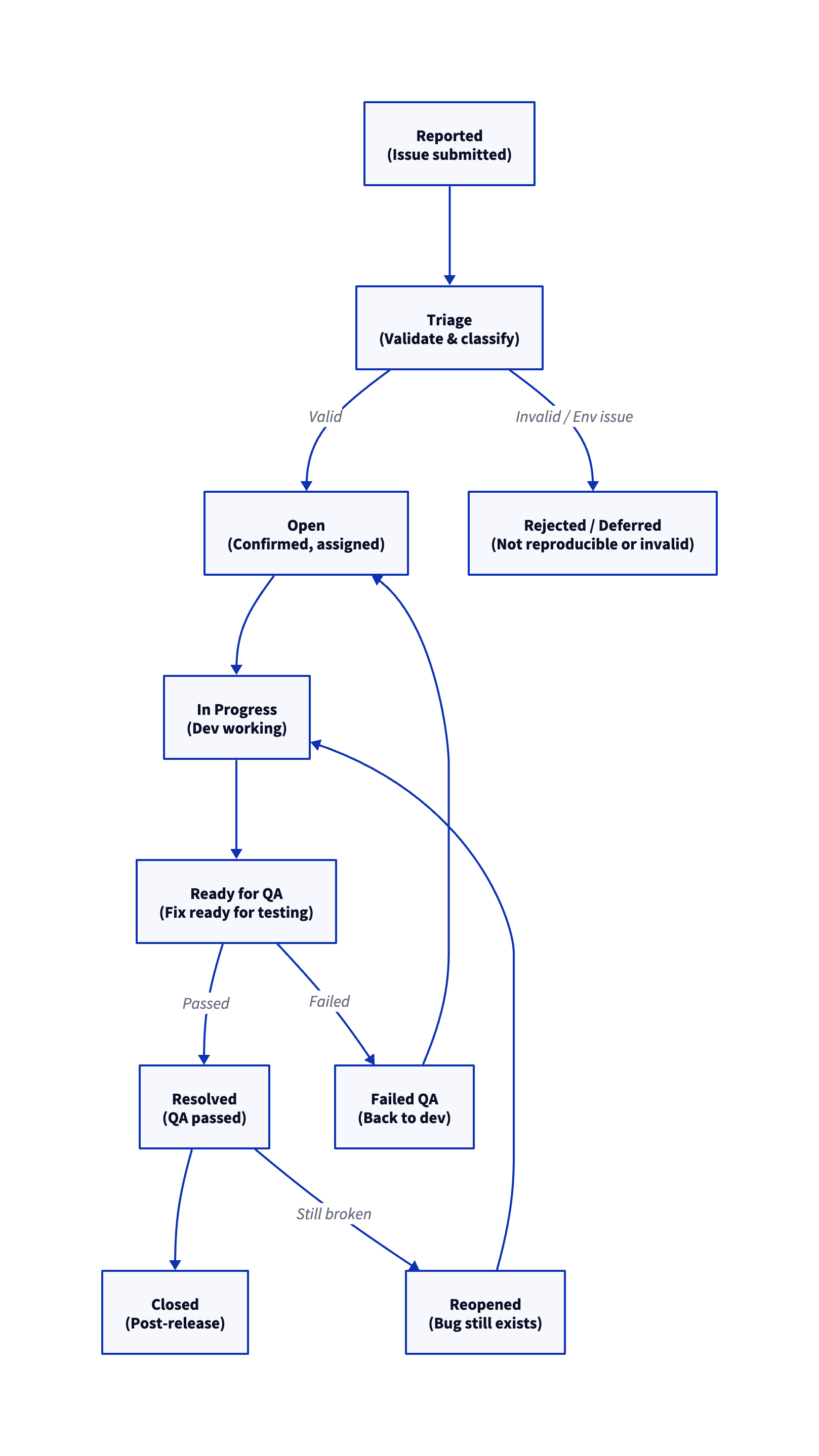
🌀 Workflow Stages
-
Reported
Initial submission of the issue by QA or tester.✅ Required fields:
- Environment details
- Steps to reproduce
- Expected vs. actual result
- Attachments (screenshots, logs)
➡️ Transition: “Triage”
-
Triage
Issue is reviewed by a triage group (QA lead, product owner, dev lead).✅ Checklist:
- Is the issue reproducible in a clean environment?
- Is the environment stable and not affected by other WIP features?
- Is this a new bug or a known issue?
- Is severity and priority set correctly?
Outcome:
- Valid → Move to To Do
- Not reproducible / invalid → Move to Rejected
- Environment issue → Move to Deferred / Needs Environment Fix
-
To Do
Bug is confirmed and ready for development.✅ Developer assigned
➡️ Transition: “In Progress” -
In Progress
Developer is working on the fix.✅ Requirements:
- Bug fix committed
- Related code peer-reviewed
- Linked to test cases (if needed)
➡️ Transition: “Ready for QA”
-
Ready for QA
Fix is deployed to test environment and awaits verification.✅ QA responsibilities:
- Retest with original reproduction steps
- Perform regression around the area
- Confirm environment is stable
➡️ Transition:
- Passed → Resolved
- Failed → Back to To Do
-
Resolved
Bug fix has passed QA validation.✅ Final verification done
➡️ Transition: “Closed” after release -
Closed
Bug is verified in production or post-release context. -
Rejected / Deferred
Bug not valid or caused by environment/integration noise.✅ Notes must be added to justify decision
➡️ Option to reopen if issue resurfaces
🔁 Optional Statuses
- Needs Info: Waiting for more details from reporter
- Environment Issue: Reassign to DevOps or Infra team
- Duplicate: Link to existing issue
Workflow Diagram
Bonus
✅ Example of a Good Bug Report
Title:
Cart total does not update after removing item
Environment:
- Staging environment
- Version: v2.3.1
- Browser: Chrome 123.0 (macOS)
- Logged-in user role: Customer
Steps to Reproduce:
- Add two items to cart
- Click on the trash icon to remove one item
- Observe the cart total at the top-right corner
Expected Result:
Cart total should update and reflect the correct amount after item removal.
Actual Result:
Removed item disappears from the list, but the total remains unchanged until page refresh.
Severity: Medium
Priority: High
Attachments:
- Screenshot of incorrect cart total
- Console log export
- Network tab showing no recalculation request sent
Additional Notes:
- Issue not present in production
- Possibly related to recent changes in cart JS event listeners (see PR #456)
❌ Example of a Bad Bug Report
Title:
Cart is broken
Steps to Reproduce:
Click around, sometimes numbers are wrong.
Expected:
It should work.
Actual:
It doesn’t work.
Severity: Urgent
Key Differences Between Good and Bad Bug Reports
| Criteria | Good Bug Report | Bad Bug Report |
|---|---|---|
| Title | Clear, descriptive, specific to the issue | Vague, ambiguous (“Cart is broken”) |
| Steps to Reproduce | Detailed, numbered, and easy to follow | Missing, unclear, or not reproducible |
| Environment | Includes version, browser, platform, user role | Not mentioned |
| Expected vs Actual | Clearly states both outcomes | Vague or missing |
| Severity/Priority | Appropriately assessed based on impact | Often exaggerated or missing |
| Attachments | Screenshots, logs, console/network details | None provided |
| Root Cause Clues | References related PRs, areas of recent change | No context or technical traceability |
| Actionability | Developer can act on it immediately | Needs clarification before triage |
Conclusion
Not all features are equally risky. By focusing effort on the most defect-prone areas — and understanding that even good systems will have some flawed features — you set realistic expectations for delivery and maintenance. Smart teams track not just how many bugs exist, but where they live and why.
This overview covers the core concepts of defect management within the software development lifecycle. If you’re looking to implement a structured SDLC, improve quality assurance, or build a mature engineering process within your team or organisation — I can help. With hands-on experience in process design, agile delivery, and technical leadership, I offer practical support to establish or refine your software development workflow from the ground up.
Get in touch to bring clarity, structure, and real momentum to your engineering efforts.
Ready to build something amazing?
Let's discuss how I can help bring your software vision to life.
Hire Me